I’ve spent most of this year helping various startups build out AI and LLM systems, and one common task is to, as quickly as possible, get an understanding for the tradeoffs between the main LLMs available. I would recommend that the analyses be lightweight enough to be built quickly and easily repeatable, for two reasons:
- Early-stage companies should focus on delivering some idiosyncratic product value; LLM selection or tuning is probably not your long-term moat
- LLM performance is advancing so rapidly - literally by the week - that evaluations should be built to be light-weight and reproducible, such that they can be re-run weekly
Previously, there was some annoying scaffolding work required to use each LLMs API and perform an apples-to-apples test. Recently, however, I started using OpenRouter, which provides a common interface from which to call most of the major LLM providers. You don’t even need provider-specific API keys. It’s incredibly lightweight, which means that you don’t have to shackle yourself to a specific framework like Langchain or Haystack (not that there’s anything wrong with either of those, but then do you want to use them in production?). Openrouter also returns useful information like token counts, per-call costs, and latency.
For the following example, an LLM is asked to analyze a transcript and rate the conversation on several dimensions, producing quantitative scores. The loss function I’m using is L2 loss, I’m calling it deviance, and we want to minimize it.
\[Deviance = \sum{(llm\_score - human\_score)^2}\]It’s worth thinking of what scoring function you want to use - given two different results, what’s the best approximation of the user’s utility?
I had previously used Claude 2, but have been really impressed by Anthropic’s latest family of models. The performance here should hopefully not be surprising. All prompts are the same, and roughly written to be optimized for OpenAI:
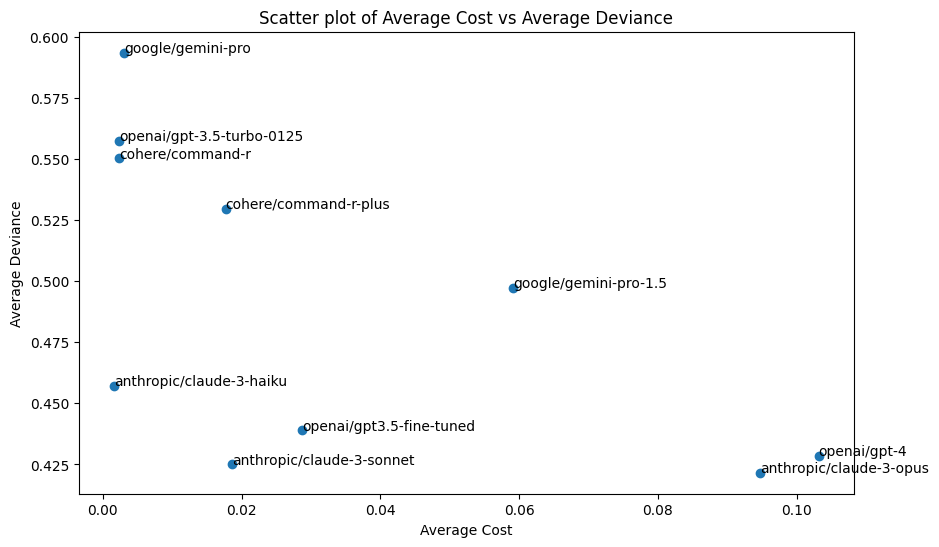
The main takeaways here are that Claude 3 is great, and fine-tuning might be worth your effort if you want faster, cheaper, GPT-4 like performance.
What about fine-tuning?
As you can see from the diagram, I included a fine-tuned GPT 3.5 in the bakeoff, and it performs very well. That said, it is strictly dominated (that is, both more expensive and less performant) by Claude 3 Sonnet.
Equally surprising - for me - was that the addition of few-shot examples did not seem to improve performance. I have two hypothesis for this
- Maybe latest models are sufficiently good reasoners to not need examples
- Maybe the cost of the large amount of text needed for examples (these are very large text documents) outweighted the benefit of the examples
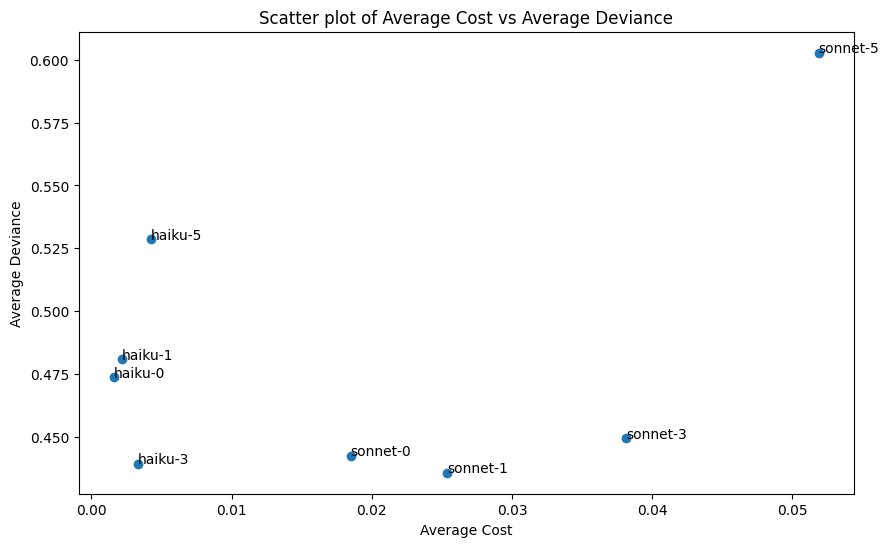
The following results graph shows cost vs. performance for N few shot examples where N is 0, 1, 3, 5. (More examples is always more expensive, because it increases the token count of the prompt).